时光机网站历史快照,建站记录查询的使用说明
再此说明一下,现在市面上所有的时光机查询历史记录的网站不管是付费的还是免费的,统一使用的接口都来自于web.archive org 这个站点(以下简称时光机),这个时光机网站从几十年前就开始在互联网上收集各种网站的缓存,因此他们的数据最全面,只不过国内无法访问。也就是说不管现在市面上哪家提供时光机快照查询的网站,他们的数据均来自于这家网站的接口。包括我们。因此就不存在数据不准确的说法,大家都一样。那为什么看到的数据有部分差异呢?这取决于我们对于数据的价值标准不同,首先我们知道每个网站不同时期可能有不同的状态码,例如正常可以访问的时候是200,如果网页不存在那就是404,有时候可能会有301,302,505之类的。在一个网站建站期间难免会出现这些状态码,那时光机缓存网页快照的方式就是不定期访问这些网站,并且把访问的数据记录下来,包括状态码以及网页源代码。如下图:
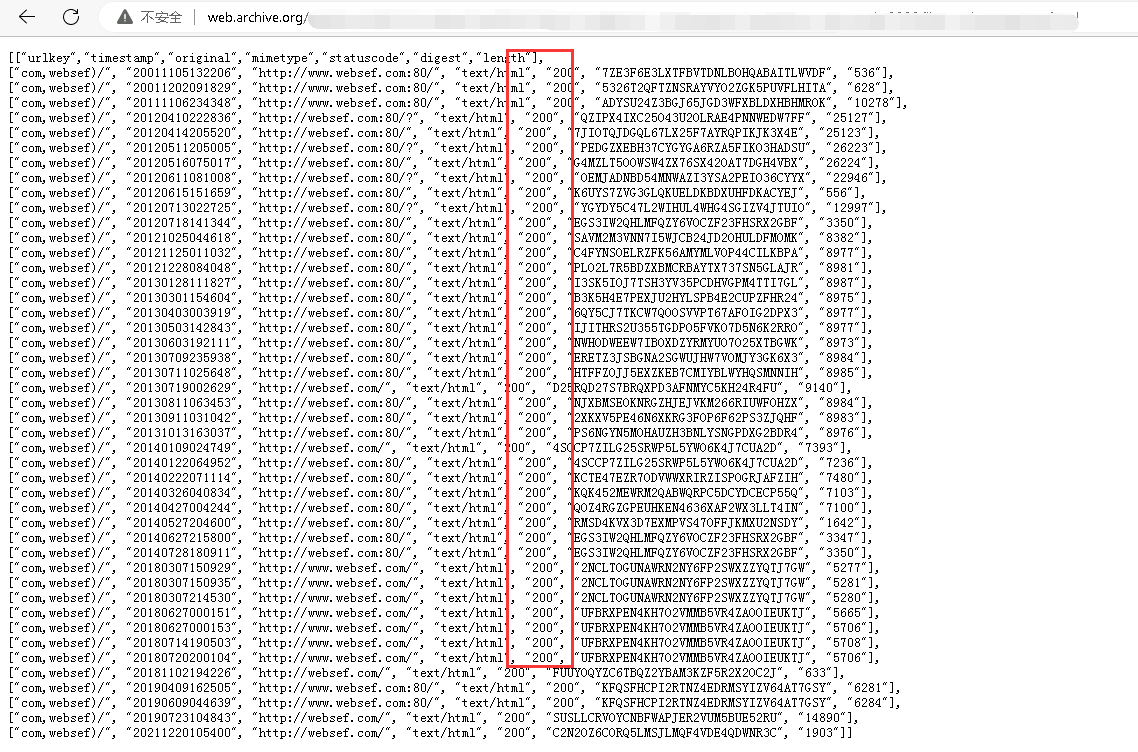
这是时光机的一个基础接口,我们“查到了”对于时光机的快照的缓存标准为,状态码为200的最新100条缓存。有些地方提供最新10条,有些地方提供最新200条,这是大家感觉数据不同的原因之一,还有我们只针对网页返回状态码为200的时光机快照进行缓存,有些人会不管200还是404都进行缓存,再比如有些人只提取<title>标题</title>这样的标题进行缓存,而我们不仅对这样的标题进行缓存还对下面
<title>
标题
</title>
这样的标题进行缓存。再比如前面我说过我们只针对网页状态200的网页进行缓存,那有些网站是301跳转,跳转后的网站我们认为参考意义不大,所以不进行缓存。再比如有些提供时光机查询的网站可能会折叠相似标题,就比如在一个月内这个网站被时光机记录了5次,但是这5次网站数据均是一样的,那么部分人会选择折叠这5个相同的标题,只显示一条,而我们是不折叠的,全部显示。以上是部分感觉数据有差异的地方。但不管怎样,我们的数据是准确的 —— 因为数据均来自于时光机。



